
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 국방AI경진대회
- 기자단
- 경제적 자유
- 확률과 통계
- 수학
- 국방부
- 미적분
- pandas
- k-digital
- ai
- 데이터 분석
- cheatsheet
- 글쓰기
- deep learning
- HTTP
- CS
- 코딩마스터스
- 코딩테스트
- 해커톤
- 코딩 마스터스
- 머신러닝
- 코딩 테스트
- 역행자
- KT 에이블스쿨
- 선형대수
- OOP
- MAICON
- transformer
- aice
- associate
- Today
- Total
처음부터 시작하는 개발자
[CS] Transformer 개요 본문
개요
딥러닝 분야에서 큰 변화를 이끈 Transformer에 대해 정리해보고자 한다. Stable Diffusion이 딥러닝 모델의 출력을 크게 향상시킨 것처럼, Transformer는 딥러닝 모델이 입력의 특징을 더욱 정확하게 파악하는 데 기여함으로써 입력 처리를 비약적으로 향상시켰다고 할 수 있다.
"Attention Is All You Need"이라는 논문이 2017년에 발표되었고, 이때 Transformer라는 모델이 처음 등장하였다. 그 이전에는 그 당시 널리 쓰이고 있던 Seq2Seq 모델을 개선하기 위해 Attention이라는 기법이 알려져 있었지만, RNN이나 CNN 등을 전혀 사용하지 않고 오직 Attention 기법만으로 모델을 구성한 것은 Transformer가 최초였다.
Seq2Seq 모델

Transformer가 등장하기 전에는 Seq2Seq 모델이 자연어 처리 분야에서 널리 사용되었다. Seq2Seq 모델의 이름에서 짐작할 수 있듯이, 이 모델은 순차적으로 단어를 입력받는 인코더와 단어를 순차적으로 출력하는 디코더로 구성되어 있다.
이 모델은 다음과 같은 문제점들을 지니고 있었다.
1. 이 모델은 인코더가 이해한 의미를 컨텍스트 벡터(z)에 저장한다. 그리고 디코더는 이 저장된 의미를 활용하여 출력을 생성한다. 하지만 복잡하거나 긴 문장 등의 입력 정보가 너무 많으면 그 의미를 한정된 크기에 컨텍스트 벡터로 처리하기에는 한계가 있었다.
2. seq2seq 모델의 RNN 구조는 다음 단계의 입력이나 출력을 생성하기 위해 이전 단계의 연산결과가 필요하다. 이런 구조는 병렬 컴퓨팅을 적용하기 어려워 모델의 성능에 악영향을 끼치는 요인이 되었다. (병목 현상)
3. RNN의 여러 레이어를 거치며 처음에 받았던 입력의 의미정보가 퇴색된다. (기울기 소멸)
Attention의 등장
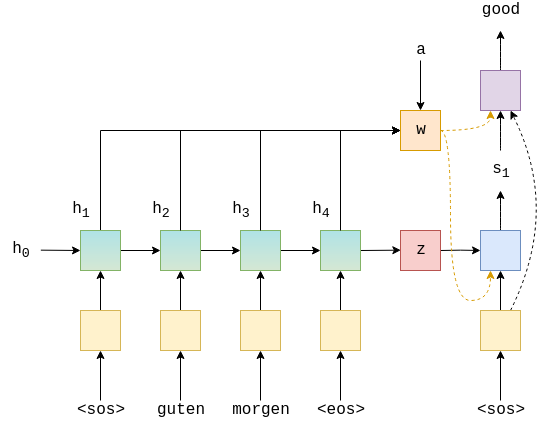
컴퓨터의 연산력이 증가하면서, 출력을 생성할 때 컨텍스트 벡터 뿐만 아니라 모든 입력을 다시 한번씩 참고하게 하자는 아이디어가 등장했다. 그런데 잘 생각해보면, 우리가 어떤 문장을 이해할 때 집중하는(attention) 특정 단어들이 존재한다. 그래서 최초의 attention 모델에서는 출력마다 참고해야 할 각 입력들이 어느 정도의 중요도를 가지는지 학습시키는 아키텍쳐(w)를 추가하였다. 이로써 어느 정도의 성능 향상을 이룰 수 있었다.
Attention의 발전, Self-Attention
셀프 어텐션(self-attention)은 어텐션 기법의 발전된 형태로, 입력 인코더 내의 모든 입력 간의 관계를 고려하는 방식이다. 초기의 어텐션 기법이 디코더가 출력을 생성할 때 어떤 입력을 중점적으로 보아야 할지 결정하는 방식이었다면, 셀프 어텐션은 각 입력(단어)이 모든 다른 입력(단어)과 어떻게 상호 작용하는지를 고려하는 방식이다. 이 말은, 각 입력이 인코더 내의 모든 입력과 어떤 관계를 맺고 있는지를 파악하여 그 중요도를 판단하게 된다는 것이 다. 이렇게 각 입력(단어)간의 상호관계를 고려하게 하여 모델이 문장의 전반적인 의미와 문맥 파악을 할 수 있도록 하였다.
Transformer가 일으킨 혁신

Self-Attention 기법이 등장하면서, 컨텍스트 벡터보다 이 Self-Attention을 통해 모델이 학습하는 정보가 더 많아지게 되었다. 이에 구글 엔지니어들은 오로지 Attention 기법만으로 모델 아키텍쳐를 구현해보았다. 그리고 이 기법을 보완하고자 Multi-Head Attetion기법을 도입했는데, 집단지성을 모방하여 Attention을 병렬로 여러개 둔 것이다. 이렇게 만들어진 Transformer는 다음과 같은 장점들을 가지고 있었다.
1. 단어의 순서와 별개로 문장 전체 단어와의 관계를 고려하므로 입력이 이전 입력에 의존하지 않는다. => 병렬 컴퓨팅을 활용하여 시간과 성능이 비약적으로 향상되었다.
2. 학습 문장을 하나만 제공하여도 모델에서는 다양한 학습 데이터가 주어진 것과 마찬가지이므로 모델의 구조가 아무리 복잡하여도 과적합에 내성이 생긴다. => 초거대 모델의 등장을 가능하게 하였다.
트랜스포머로 인해 BERT, GPT 등이 등장하였고, 이전 모델보다 성능이 급격하게 향상되었다. 또한, 트랜스포머의 구조는 자연어처리에만 국한되지 않고 컴퓨터 비전(Vision Transformer), 다양한 입력처리(Multimodal) 등에 활용되며 새로운 표준으로 자리잡았다.
해당 깃허브에서 seq2seq에서 transformer까지의 발전사를 경험해볼 수 있다.
'CS' 카테고리의 다른 글
| [CS] HTTP의 개념 (0) | 2023.12.10 |
|---|---|
| [CS] AI를 위한 수학 (0) | 2023.12.02 |
| SQL for Data Analysis Cheat Sheet (0) | 2023.11.17 |
| [CS] Apache Tomcat 개요 (0) | 2023.11.09 |
| [CS] 객체지향 프로그래밍 (0) | 2023.10.15 |

